 Github: link
Github: link
Project Idea
Having finished Road to React, I wanted to do a project to further internalize what I’d learned as well as prove proficiency. Ideally, of course, I wanted to spend my time on something with a pretty clear use case and something which wasn’t a paint-in-the-lines dummy project. The low-hanging fruit of “simple but useful” in general is hard to find, but I kept an eye out for niches.
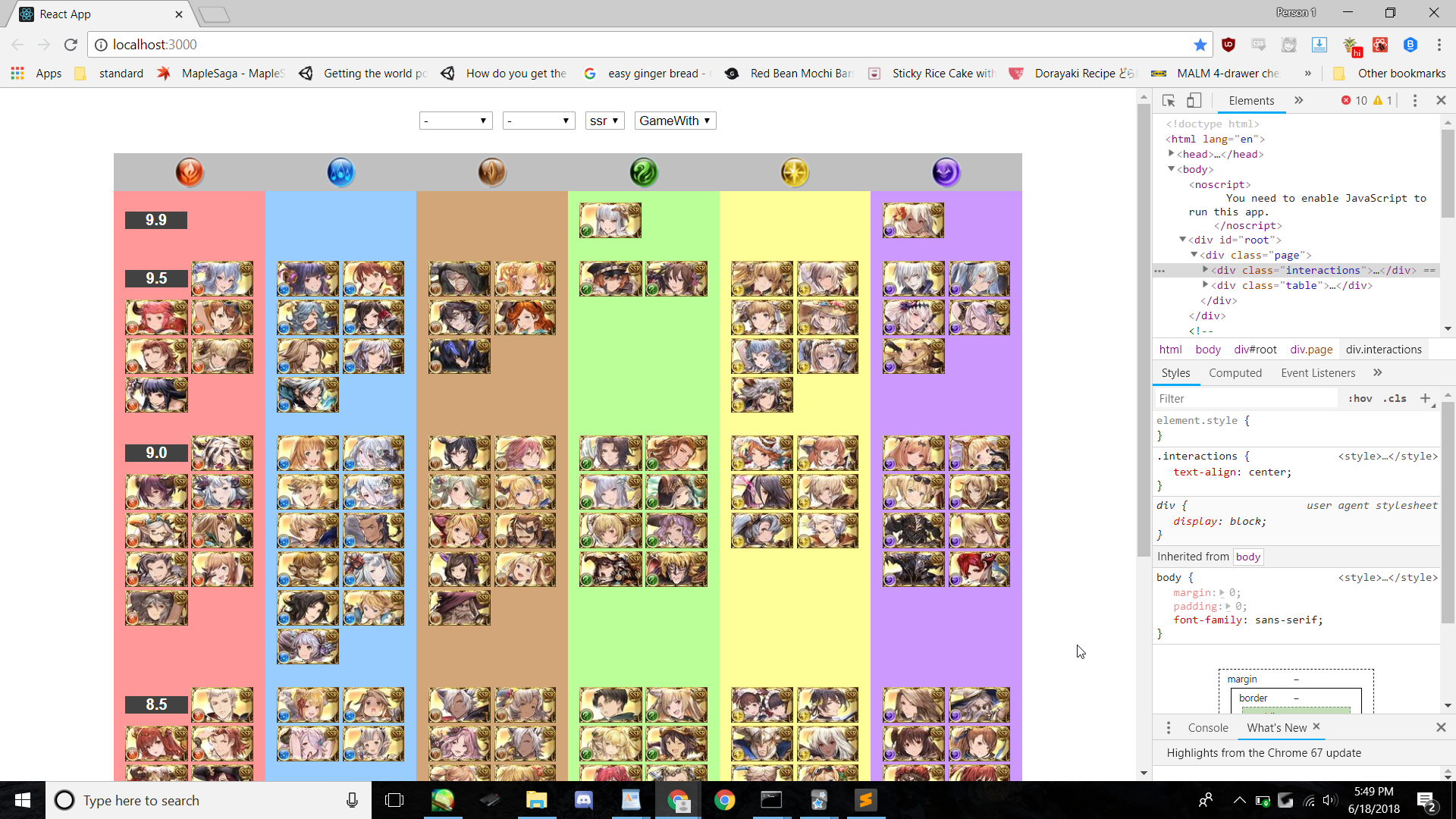
Granblue Tier List
This is the most popular tierlist among English-speaking Granblue players. However, Google Sheets isn’t ideal.
- The high amount of images seems to cause problems- character images often load in the wrong position.
- There’s no automatic or variable sorting. It’s hand-sorted and can’t be changed.
- Looking up character information is done individually. If someone sees a character they’re interested in knowing more about, they have to click on the tab for element and either search the character or, if they don’t know the name, scroll through looking for the character image.
Furthermore, there is another tierlist of note- the Gamewith tierlist. This gives us another problem: 4. A person who wants to see both tierlists has to go to two sites.
The ideal tier list
Let’s say the basic format, as of the General/Advanced tabs, is preserved. Problem 1. and 2. require few or no UI changes. 3. can be remedied by having clicking on the character portrait open a popup with more information. 4. can be solved by having both sets of ratings saved and allowing switching between them as with the General/Advanced ratings. Better yet, a character’s popup should contain all ratings, no matter which set of ratings was being viewed, so that it isn’t necessary to navigate to another set of ratings and find the character all over again.
Technologies
There are a few components here.
- A React app, as stipulated.
- Data- character tier scores, character attributes for sorting…
- A way to get the data.
An option is, of course, to just hardcode the data right into the react app, “doing away with” 2. and 3. Since there seem to be ca. 150 characters worth including on the tierlist as of the time of writing, this is probably personally doable or buyable. That said, it’s inelegant, not very extensible, and generally unimpressive. Better to scrape the data into a database.
Process
What order to do things in after that doesn’t have a single answer. Is the answer to completely flesh out the ideal front-end, then the ideal server, then ideal scraping? Probably not. Is the answer to create a Minimum Viable Product? Maybe. What counts as a minimum viable product depends on the audience, after all.
In any case, I started off by pulling out the guts of the Road to React Hackernews project and setting up a simple table with dummy data.
Next, I set up a server which can respond to a GET request and has dummy data in a SQLite backend.
Database consideration
Why SQLite? Originally, I considered MongoDB, as in the MERN stack, but on further investigation decided to use SQLite. Firstly, the data for characters is very structured and seems suited for a relational database. Secondly, SQLite, with data being embedded into the server, seems well- suited for such a lightweight use case, even if features involving writing (such as being able to vote on character scores) were added. (See: here).
Scraping I
My original goal was to use React, and additionally the app is fairly useless without a properly set up frontend- but, on the other hand, it’s easier to see how things will really look on the frontend if the real data is at hand. Dummy data could be typed out or randomly generated, but that seems like relatively unneccessary effort. As such, I decided to scrape some character data first.
There are a few sources: the wiki, the GBF Gaijins tierlist on Google Sheets, and the Gamewith tierlist. I started by looking at the wiki.
Scraping the wiki
Mediawiki has an API which could probably be used to get relevant data for each character. Is there an easier way? Well, the tracker already asks the API for the information we want, so scraping that page works fine! This does mean relying on an extra layer on top of the API not to break, but this is an acceptable sacrifice at this point in time.
The function which scrapes and formats the data (using cheerio) is called with a callback to insert the results into the database. In the future this can be automated (with backups in case something goes wrong).
Scraping the GBF Gaijins tierlist?
This is trickier. There’s a General tier list, an Advanced tier list, and pages with more detailed assessments. The full tier lists (General/Advanced pages) only have images, and not names that would make it easy to associate scraped rankings with characters. The more detailed write-ups sometimes list names inconsistent with the names scraped from the wiki, but thankfully the names link to the corresponding wiki page, such that the “true” name can be extracted with a bit of effort. However, only the detailed write-ups for Fire have the Advanced rating accessible.
This leaves us with the problem that, if relying on the rest to be correspondingly updated is undesirable, only the General/Advanced pages with character portraits instead of names serves as identification. This isn’t an insurmountable obstacle, though! Scraping the wiki-provided urls for each character’s portrait and matching each portrait from the tier list to its closest match from the wiki should allow uniquely identifying each character.
However, since the process will be different, and the wiki data alone provides something to model the frontend with, I decided to leave this be until later.
Hooking things up
Trying to have the React app GET character info initially failed. The first solution was to enable CORS. The second was to add/fix async code. The function which queries the database returns a promise.
Character table
Firstly, the list of characters is sorted/grouped by tier and element.
This is not as simple as it seems. The obvious choice is a table, but, that said, what if ie. I might want the appearance of items being grouped by column? In that case it seems more flexible to use divs and group by column instead of row. However, if we assume fixed size for character portraits, then cell height will naturally vary and will need coordination. This shouldn’t be too difficult, though, as it just means for each tier, counting characters per element, choosing tier cell height based on the greatest number, and passing this information to element columns.1
Filtering
App has filterStates, an object which has keys for each attribute (aka filter type) to filter by (eg. element, style, weapon proficiency) whose values are either null or the filter value (eg. fire, defense, or sword, respectively). A Filter component, which is a controlled component, takes a key-value pair, uses the key to look up the list for an attribute containing all possible attribute values, and either uses the value as the selected value, or if it’s null, uses the default value.
Hosting
Steps:
- Create an AWS account. Instantiate an EC2 t2.micro instance.2
- Using Putty convert the .pem file to .ppk. In Putty, go to connection->ssh->auth and use the .ppk. In session use public ip address. Open the connection and login as ec2-user.
- Install node and git. (If using amazon linux (not ubuntu), use yum instead of apt-get.)
- Git clone app directory and run npm install in the folder with package.json.
- npm install -g forever.
- Changing security group permissions for the ec2 instance to allow http and https (that is, allow access on certain ports).3
- sudo amazon-linux-extras install nginx1.12, then sudo service nginx start to show the default nginx page.4
- Set up available-sites and sites-enabled directories in /etc/nginx, symlink them, and include sites-enabled in nginx.conf. (This is apparently more maintainable in the long run.)5
- Set up a nginx config file (.conf).6
- Add server_names_hash_bucket_size 64; in the http block in /etc/nginx/nginx.conf.7
- forever start app.js instead of node app.js, forever start -c “npm start” /path/to/app/dir/ instead of npm start.8
Link: here (WIP- will show Bad Gateway if the React app isn’t running.)
Scraping the GameWith tierlist and matching tiers to characters
Basically the same as scraping the wiki. Tier ranking and image are scraped. However, in this case we don’t want to save the image, just get a perceptual hash of it and use that to match a tier ranking to a corresponding character ID. Firstly, to avoid recalculating known hashes each time, each known character image is hashed and saved to the database. Once that prepwork is done we move on to the actual scraping and comparing. The modules used are imghash for perceptual hashing and hamming-distance for, well, hamming distance (for comparison).
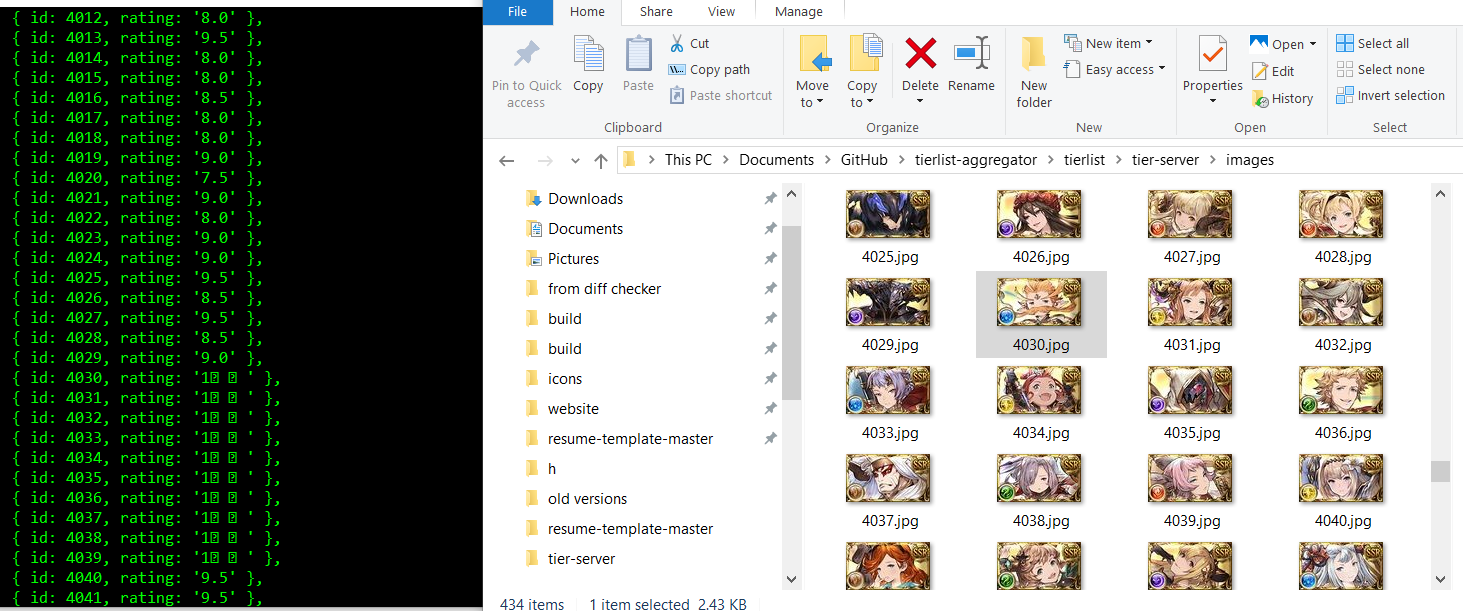 And it works! (4030-4039 are a special type of character, and don’t have an explicit tier on the list- that’s some Japanese text instead, as expected.)
And it works! (4030-4039 are a special type of character, and don’t have an explicit tier on the list- that’s some Japanese text instead, as expected.)
Restructuring (Database and API)
The main table of character info from the wiki was extended with a column for GameWith tier data. In this sense it muddies the cleanliness of having data from each table come from a seperate souce. In the sense of division of responsibilities, however, it’s equally clean- it divvies data up by when it will be used. The tier ranking is needed right away to contruct the table, whereas any extraneous data from a tierlist like the GBF Gaijins one will only be seen once the app user chooses a character to investigate further.
Furthermore, the API’s urls were brought in line with convention. Current API urls are /characters, /character/:id, /character/:id/image, where the colon denotes a variable.
To-do list (no particular order, but new things to do generally added up top)
- Split up (rebase) large git commit (low priority)
- Scrape new characters from the wiki
Update wiki data (weapon proficiencies are missing)Add more safety against incorrectly identifying a character by portrait(Not failproof, but it’s better now)Correctly ordering characters by tierExtend API so the React app can access character imagesFixing incorrectly downloaded character imagesFiltering in the React AppIdentifying images with the phash libraryScraping the Gamewith tierlist- Scraping the GBF Gaijins tierlist with the Google Sheets API
Hosting- Caching with nginx
Fix CSS- Beautify CSS
- Automate scraping
Retrospective (6⁄20)
Site not currently up (hosted on AWS)- it wasn’t currently of use, and I’ve stopped playing Granblue. As such I have little motive to continue working on it, as I feel like I’ve plucked the low-hanging fruit so far as my learning goals go.
If I were to do the project again I would’ve picked a NoSQL database for the ability to restructure data more easily, as that turns out to be a hassle! There’s also no need for complex transactions, and a need for speed.
I would also look into containerization- a dependency issue became an annoyance even for a relatively simple project like this.
- Later on columns and rows may not always be elements and tiers, but for simplicity’s sake I refer to them here as though they are unquestionably linked. ↩
- 1-5: http://iconof.com/blog/how-to-install-setup-node-js-on-amazon-aws-ec2-complete-guide/ ↩
- 6. http://oliverelliott.org/article/computing/tut_aws/#EnablingPermissions ↩
- 7, 9. https://www.codefellows.org/blog/hosting-a-website-on-a-free-aws-ec2-instance-not-for-the-faint-hearted/ ↩
- 8. https://stackoverflow.com/questions/17413526/nginx-missing-sites-available-directory ↩
- 9. https://medium.com/@utkarsh_verma/configure-nginx-as-a-web-server-and-reverse-proxy-for-nodejs-application-on-aws-ubuntu-16-04-server-872922e21d38 ↩
- 10. https://stackoverflow.com/questions/13895933/nginx-getting-error-with-specific-domain-name ↩
- 11. https://github.com/foreverjs/forever/issues/540#issuecomment-37762716 ↩